再让AI大厂这么“偷”下去 咱就看不到免费的网站了
最近,谷歌发布了一份令人意外的隐私政策更新,明确表示他们将使用公开的在线数据来训练自家的 AI 模型。换言之,根据新政策,谷歌有可能抓取你在网上公开发布的所有信息,包括但不限于帖子、搜索关键词和观看过的视频。
最近,谷歌发布了一份令人意外的隐私政策更新,明确表示他们将使用公开的在线数据来训练自家的 AI 模型。换言之,根据新政策,谷歌有可能抓取你在网上公开发布的所有信息,包括但不限于帖子、搜索关键词和观看过的视频。
这不妥妥的互联网裸奔吗!
OpenAI 刚刚被控侵犯数据隐私不久,谷歌就急着冲上来与之抢夺头把交椅。显然,这一动作很有可能与数据付费紧密相关。谷歌不去抓这波免费的数据,未来很可能再也无法得到了。实际上,自从 ChatGPT 大火之后,这个话题就再也没平息过。

今年 3 月,马斯克首先举起了数据付费的大旗,宣布 Twitter 的 API 接口将不再免费使用。紧接着,就是 Reddit 上一个月的“停电”抗议活动,抗议的正是官方的数据付费政策。从那时以后,大多数第三方软件已宣布停止开放,Reddit 决心向数据收费迈进。
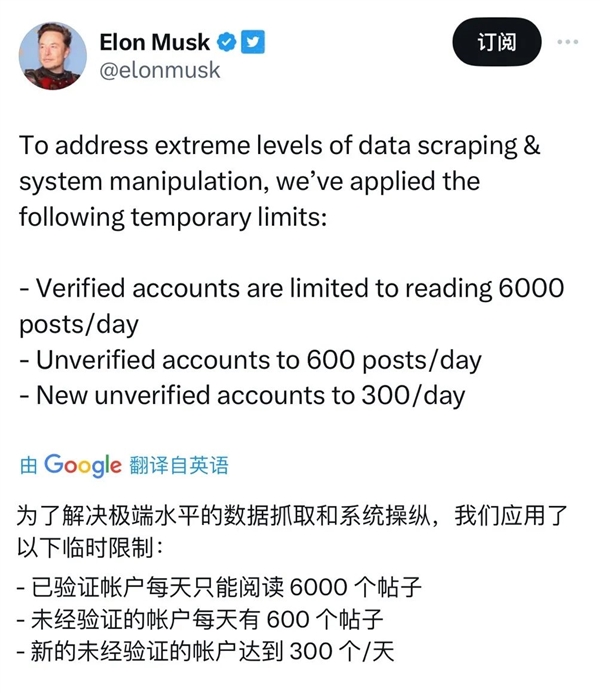
最近一段时间,Twitter 又出现了限制流量的事件,没有付费认证的账号每天只能阅读 600 条帖文,目的是为了阻止机器人获取用户数据。
难道数据就这样变得如此珍贵了吗?实际上,这或许与 AI 有一定关系。毕竟,要让 AI 大型模型变得更加智能,就需要源源不断的数据来“喂养”。
现在能够制作大型模型的公司,要么是自己有丰富的数据,像百度、阿里和腾讯,要么是爬取别人的数据,这里特别点名的是 OpenAI。
因为许多网站都提供免费的 API 接口,为微软和 OpenAI 这些巨头提供了机会。但是现在情况不同了,AI 重新赋予了数据价值之后,有了牌照的平台肯定不愿意再被白嫖了。即使是 Reddit 的 CEO 霍夫曼也公开说:他们不想再免费提供数据给这些巨头。
所以,OpenAI 被起诉很可能是大型平台们联合起来的一种“杀鸡儆猴”行动,以此来制止 AI 这一歪曲风气。但是,法律是否会站在 OpenAI 这一边,还真是难说。
因为数据版权涉及到三个关键问题:
1. 数据爬虫行为本身是否合法?
2. 数据是否受版权保护?
3. 用数据生成的作品是否受版权保护?
首先,第一个问题是指获取数据的方式,无非是付费购买或者收集公开的数据。但需要注意的是,公开的数据并不等同于被授权使用,还要看网站是否对数据爬虫行为有限制条款。
如果越过版权方的同意、或者绕过网站的限制强行获取数据,那就是明确的非法入侵计算机信息系统罪。即使 OpenAI 声称他们爬取的是公开网站的数据,数据爬虫行为本身是否合法,还要看版权方是否授权。
其次,关于数据本身是否受版权保护。根据美国版权法,如果 AI 模型所使用的训练数据符合“合理使用”的范围,就不构成侵权。

但问题在于“合理使用”的界定。其中包括商业用途是否涉及、原始作品是否受版权保护、使用的数量和对原作产生的影响等四个标准。像新闻报道、学术研究,适当引用是完全可以的。
但是,对于拥有数以亿计使用量的 AI 模型和商业化的 AI 软件来说,它们还能被视为“合理使用”吗?最后,是关于 AI 生成作品的版权问题。
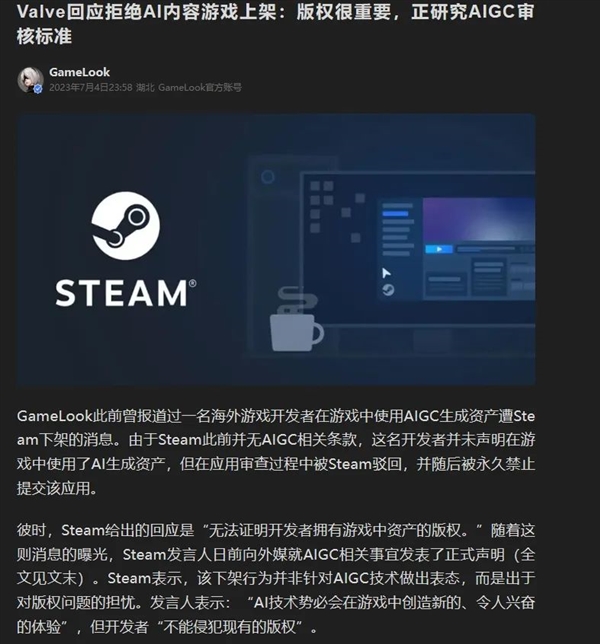
由于训练数据的版权难以厘清,AI 生成的内容自然也会出现版权争议。就在前几天,Steam 甚至下架了一款使用 AIGC 生成的游戏,指认版权存在问题。
以 AI 绘画为例,图像生成相当于重组和重新装配,虽然最终结果是全新的,但仍然保留了一些训练图像的特征。但这种情况到底算不算侵权,各国有不同的观点。
因为训练数据属于他人,美国版权局认定由 AI 生成的作品不受版权法保护,甚至可能侵犯著作权。
而日本政府则持完全不同的态度,表示日本法律不保护 AI 训练所使用数据的版权。至少在现有法律框架下,这些问题很难得到统一的答案。既然监管力度有限,版权方只能亲力亲为,开始收费,尽快追讨权益。

可以预见,在推特和 Reddit 之后,也许还会有更多内容版权方立起高墙。对于平台来说,这当然是一条获利的新路径,科技巨头也需要付出更多的金钱。但对于整个互联网来说,这可不是一件好事。
当年,互联网以开放共享的基因诞生,例如维基百科和推特一直免费提供 API 接口,以方便开发者调用数据。
然而,如果数据收费成为现实,那将带来无法预料的后果。小型开发者很难承担庞大的数据费用,如果创新只限于巨头内部,那不就是纯粹的垄断吗?
尤其令人担忧的是,很多现在免费访问的网站可能会变成付费网站,这对于像我们这样的普通用户来说是个打击。
实际上,不能完全怪平台收费数据,毕竟巨头们的 AI 技术太过强大,让人有些胆怯。他们这样做也是为了自保,只能说是无奈之举。尽管谷歌有“隐私政策”作为保护,但结果如何还真不好说。关键是我们需要看监管的强力介入何时能落实。
澄清数据版权是 AI 发展中无法绕过的难题,而现在,似乎也关乎着互联网未来的走向。我们无法预测 AI 这艘船会将我们带向更加开放还是封闭的时代。
再让AI大厂这么“偷”下去 咱就看不到免费的网站了 - Extfans”