谷歌更新隐私政策规定,可使用互联网上的公开信息训练 AI 模型
数据,是 AI 技术发展的其中一大要素,也一直是科技巨头们“斗争”的焦点。近期,搜索引擎巨头谷歌对其隐私政策进行了更新,明确表示公司将保留获取用户在网上发布的内容来训练其人工智能工具的权利。
数据,作为人工智能技术发展的三大关键要素之一,在科技巨头的竞争中一直备受关注。近日,搜索引擎巨头谷歌对其隐私政策进行了更新,明确表示公司将利用公开信息来训练其人工智能工具。
谷歌最新的隐私政策更新内容如下:
谷歌将利用信息来改进我们的服务并开发新产品、功能和技术,使我们的用户和公众受益。例如,我们将使用公开信息来帮助训练谷歌的 AI 模型并构建Google Translate 、 Bard 和 Cloud AI 等产品和功能。
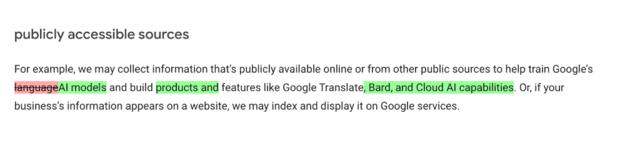
这也意味着,谷歌现在能够收集互联网上公开可获取的信息或来自其他公共来源的信息,以帮助训练谷歌的人工智能模型,并打造实用的功能,例如谷歌翻译、 Bard 和谷歌云 AI。同时,本次隐私政策将“语言模型”改为“人工智能模型”。
谷歌将能够使用互联网上公开可取得的信息来开发更为全面的自家人工智能产品,而不仅仅局限于单一的功能。但需要说明的是,目前中文版的隐私政策规定尚未作出相应的调整。
对此,外媒 Engadget 进行了评论,称:“谷歌将明确告知用户,他们在互联网上公开发布的任何信息都有可能被用来训练 Bard,以及其他由谷歌开发的生成式人工智能产品。”
包括 ChatGPT 在内的 AIGC 系统一直依赖互联网上的数据进行训练,因此引发了大量关于版权和隐私方面的争议。
此前,有报道称,两名作者在美国旧金山联邦法院对 OpenAI 提起了诉讼,指控 OpenAI 滥用他们的作品来训练 ChatGPT。这两名分别来自美国马萨诸塞州的作家 PaulTremblay 和 MonaAwad 称,ChatGPT 未经他们允许,从大量图书中复制提取内容,侵犯了他们的版权。
训练先进的人工智能系统需要大量的数据材料,这种使用方式在法律方面面临一系列挑战。例如,源代码所有者将指责矛头对准了 OpenAI 和微软旗下的 GitHub;视觉艺术家们起诉了 StabilityAI 、 Midjourney 以及 DeviantArt 等人工智能工具。被告方则认为,这些系统是合理地使用了有著作权的作品。
谷歌更新隐私政策规定,可使用互联网上的公开信息训练 AI 模型 - Extfans”